Introduction: When Tests Aren’t Enough
In 2014, Amazon Web Services prevented a catastrophic S3 outage using a programming language most developers have never heard of. The bug wasn’t caught by their extensive test suite, which had excellent coverage. It wasn’t caught by code review, performed by some of the industry’s best engineers. It was caught by TLA+, a formal specification language that can mathematically verify system properties across billions of possible states.
The bug? A subtle race condition in S3’s replication protocol that would only manifest under specific network partition scenarios—exactly the kind of edge case that’s nearly impossible to catch with traditional testing but trivial to find with formal methods. You can read more about how AWS uses formal methods in this paper.
This raises an uncomfortable question: if 95% test coverage can still miss catastrophic bugs, what are we really testing?
The Problem with Testing
Traditional testing is example-based. You write test cases that check specific scenarios:
def test_mutex_prevents_concurrent_access():
mutex = Mutex()
process1 = Process(mutex)
process2 = Process(mutex)
process1.acquire()
assert not process2.can_acquire() # Checks ONE scenario
This test verifies one particular execution path. But what about:
- The 10^15 other possible interleavings?
- Race conditions that only appear under specific timing?
- Deadlocks that emerge from complex state interactions?
Formal methods don’t check examples—they prove properties. A TLA+ specification can verify that “at most one process holds the mutex” across all possible executions. Not 1,000 test cases. Not 1,000,000. All of them.
The Accessibility Problem
So why isn’t everyone using TLA+? Because it looks like this:
Next ==
\/ \E p \in Processes:
/\ pc[p] = "idle"
/\ critical = {}
/\ critical' = {p}
/\ pc' = [pc EXCEPT ![p] = "critical"]
\/ \E p \in Processes:
/\ pc[p] = "critical"
/\ critical' = {}
/\ pc' = [pc EXCEPT ![p] = "idle"]
For most developers, this is a significant barrier. Learning TLA+ requires understanding temporal logic, state machines, and a syntax that feels foreign compared to modern programming languages. Companies like AWS and Microsoft have the resources to train engineers in formal methods. Most don’t.
What if we could make TLA+ as accessible as writing a test case?
That’s the mission behind Symbolic: a project I’m building to translate natural language specifications into formally verified TLA+ code using large language models. This post introduces the architecture and explains the key design decisions.
The Planned Architecture: From Natural Language to Mathematical Proof
How do you turn a sentence like “users can’t overdraw their account” into something a computer can verify across $10^{15}$ states? The answer is a carefully designed pipeline that combines natural language processing, large language models, and formal verification tools.
System Overview
Symbolic will use a six-stage pipeline with feedback loops:
┌─────────────────┐
│ Natural Language│ "A mutex ensures mutual exclusion"
│ Input │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Preprocessor │ Extract: processes, variables, invariants
└────────┬────────┘
│
▼
┌─────────────────┐
│ LLM Generator │ Llama 3.2-8B (fine-tuned)
│ (w/ LoRA) │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Postprocessor │ Clean markdown artifacts, ensure structure
└────────┬────────┘
│
▼
┌─────────────────┐
│ Syntax Validator│ TLA+ parser (SANY)
└────────┬────────┘
│
▼
┌─────────────────┐
│ TLC Validator │ Model checker (semantic verification)
└────────┬────────┘
│
▼
┌───┴────┐
│ Valid? │───NO──┐
└───┬────┘ │
│ YES │
▼ ▼
┌────────┐ ┌──────────────┐
│ Output │ │ Refinement │
│ TLA+ │ │ Loop (retry)│
└────────┘ └──────┬───────┘
│
└──────┐
│
[Back to Generator]
Let’s examine each component in detail.
Stage 1: Natural Language Preprocessing
The preprocessor’s job will be to extract structured information from unstructured text. While the LLM could theoretically do this, separating it into a dedicated stage provides:
- Faster iteration (no LLM call needed for debugging)
- Explicit context for prompt engineering
- Deterministic parsing of common patterns
Implementation:
class NLPreprocessor:
"""Extracts concepts from natural language input."""
PROCESS_KEYWORDS = {"process", "thread", "node", "agent"}
VARIABLE_KEYWORDS = {"variable", "state", "counter", "lock"}
INVARIANT_KEYWORDS = {"always", "never", "must", "ensures"}
def preprocess(self, text: str) -> ExtractedConcepts:
normalized = self._normalize_text(text)
return ExtractedConcepts(
processes=self._extract_processes(normalized),
variables=self._extract_variables(normalized),
invariants=self._extract_invariants(normalized),
actions=self._extract_actions(normalized),
temporal_properties=self._extract_temporal_properties(normalized)
)
Pattern Recognition Examples:
| Input Pattern |
Extracted Concept |
Reasoning |
| “two processes compete” |
processes = {"p1", "p2"} |
Numeric detection |
| “mutex ensures mutual exclusion” |
variables = {"critical", "pc"} |
Domain knowledge (mutex → critical section) |
| “at most one process” |
invariants = ["Cardinality(critical) <= 1"] |
Quantifier detection |
| “acquire and release” |
actions = ["acquire", "release"] |
Verb extraction |
Why This Matters:
When building the LLM prompt, this context can be injected:
Natural Language: "A mutex ensures mutual exclusion"
Extracted Context:
- Processes: p1, p2
- Variables: critical, pc
- Invariants: at most one process in critical section
- Actions: acquire, release
Generate a TLA+ specification that...
Initial experiments show this dramatically improves generation quality by giving the LLM structured information instead of raw text.
Stage 2: LLM-Based TLA+ Generation
This is where the magic happens—but also where the complexity lies.
Model Selection: Why Llama 3.2-8B?
| Model |
Pros |
Cons |
Decision |
| GPT-4 |
Best reasoning, strong few-shot |
Closed API, can’t fine-tune, expensive ($0.03/1K tokens) |
❌ |
| Claude 3 |
Great for structured output |
Can’t fine-tune, rate limits |
❌ |
| Llama 3.2-8B |
Open source, fast inference, fine-tunable |
Needs fine-tuning for TLA+ |
✅ |
The key hypothesis: Fine-tuning an open-source model will beat prompt engineering a closed model for domain-specific tasks like TLA+ generation.
Fine-Tuning Configuration
from transformers import AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
from bitsandbytes import BitsAndBytesConfig
# 4-bit quantization for memory efficiency
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# LoRA configuration
lora_config = LoraConfig(
r=16, # Rank (controls adapter capacity)
lora_alpha=32, # Scaling factor
target_modules=["q_proj", "v_proj"], # Adapt attention layers
lora_dropout=0.05,
bias="none"
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-8B",
quantization_config=bnb_config,
device_map="auto"
)
model = get_peft_model(model, lora_config)
Why LoRA (Low-Rank Adaptation)?
Full fine-tuning of an 8B parameter model requires:
- Memory: ~32GB GPU RAM
- Time: 40+ hours on a single GPU
- Cost: $500-1000 on cloud GPUs
LoRA adaptation requires:
- Memory: ~12GB GPU RAM (fits on free Colab!)
- Time: 4-6 hours
- Cost: $0 (using free tier)
LoRA works by freezing the base model and training small adapter matrices that modify attention projections. The adapters are only 45MB compared to the 13GB base model.
Prompt Engineering
Even with fine-tuning, prompt structure matters:
def _build_prompt(self, natural_language: str, context: ExtractedConcepts) -> str:
return f"""You are an expert in TLA+ formal specifications.
Natural Language Description:
{natural_language}
Extracted Context:
- Processes: {", ".join(context.processes)}
- Variables: {", ".join(context.variables)}
- Invariants: {"; ".join(context.invariants)}
Generate a complete TLA+ module with:
1. MODULE declaration and EXTENDS clause
2. VARIABLE declarations
3. Init predicate (initial state)
4. Action predicates (state transitions)
5. Next predicate (all possible actions)
6. Invariants to verify
TLA+ Specification:
"""
Key Design Decision: Why include extracted context?
Early prototyping with base models suggests:
- Without context: ~60% syntax error rate (estimated)
- With context: ~30% syntax error rate (target)
- With context + fine-tuning: <10% syntax error rate (goal)
The combination of preprocessing and fine-tuning should be crucial to achieving production-quality results.
Stage 3: Postprocessing - Making LLM Output Parser-Ready
The Problem: LLMs are trained on code from the internet—Stack Overflow answers, GitHub READMEs, blog posts, documentation. This means they’ve learned that “code” often appears wrapped in markdown, surrounded by explanatory text, or includes inline comments explaining their reasoning.
When prompted to generate TLA+, a model might produce:
Here's the TLA+ specification you requested:
```tla
---- MODULE Mutex ----
\* This is a simple mutex specification
VARIABLE critical, pc
Init ==
/\ critical = {}
/\ pc = [p \in {1,2} |-> "idle"] \* Both processes start idle
...
====
This specification ensures mutual exclusion by…
Or it might include natural language mixed with code:
First, we declare the variables:
VARIABLE critical
Then we define the initial state:
Init == critical = {}
**The Cleanup Tasks:**
The postprocessor needs to extract clean, parseable TLA+ from this messy output:
```python
class TLAPostprocessor:
def process(self, raw_output: str) -> str:
# Remove markdown code fences
cleaned = re.sub(r'```(?:tla|TLA)?\n(.*?)```', r'\1', raw_output, flags=re.DOTALL)
# Remove common prefixes/suffixes (e.g., "Here's the specification:")
cleaned = re.sub(r'^.*?(?=----\s*MODULE)', '', cleaned, flags=re.DOTALL)
cleaned = re.sub(r'====.*?$', '====', cleaned, flags=re.DOTALL)
# Remove inline comments that are really LLM explanations
# (More sophisticated filtering may be needed)
# Ensure required structure
if not re.search(r'---- MODULE \w+ ----', cleaned):
cleaned = f"---- MODULE Generated ----\n{cleaned}"
if '====' not in cleaned:
cleaned += "\n===="
return cleaned.strip()
Why This Matters:
The TLA+ parser expects pure TLA+ syntax. Any extraneous text—even a single “Here’s your code:” prefix—will cause a parse error. The postprocessor acts as a bridge between “LLM conversational output” and “strict parser input.”
This is likely not exhaustive—as the system is tested with real model outputs, more edge cases will emerge (JSON formatting, escaped characters, hallucinated syntax extensions, etc.). The postprocessor will evolve to handle these as they’re discovered.
Stage 4: Syntax Validation with SANY
SANY (Syntactic Analyzer) is the official TLA+ parser, part of the standard TLA+ Tools distribution. It performs static analysis to catch:
- Missing MODULE declaration
- Unbalanced operators (
/\ without matching \/)
- Undefined variables
- Type errors (TLA+ is untyped, but has conventions)
Integration:
class SyntaxValidator:
def validate(self, spec: str) -> Tuple[bool, List[SyntaxError]]:
# Write to temp file
with tempfile.NamedTemporaryFile(suffix='.tla', delete=False) as f:
f.write(spec)
temp_path = Path(f.name)
# Run SANY (TLA+ parser)
result = subprocess.run(
['java', '-cp', str(self.tla_tools_path), 'tla2sany.SANY', str(temp_path)],
capture_output=True,
text=True,
timeout=30
)
# Parse errors
errors = self._parse_sany_output(result.stdout + result.stderr)
return len(errors) == 0, errors
Example Error:
Input: VARIABLE x, y
Output: line 5, col 12: Unknown operator: /\\
This gives us precise line/column information for refinement.
Stage 5: Semantic Validation (TLC)
TLC is a model checker. It:
- Enumerates all reachable states
- Checks invariants at each state
- Searches for deadlocks, liveness violations
Example:
---- MODULE BrokenMutex ----
EXTENDS Naturals
VARIABLES critical
Init == critical = {}
Enter(p) ==
/\ critical' = critical \cup {p} (* BUG: No mutual exclusion check! *)
Next == \E p \in {1, 2}: Enter(p)
MutualExclusion == Cardinality(critical) <= 1
====
TLC will find:
Invariant MutualExclusion is violated.
State 1: critical = {}
State 2: critical = {1}
State 3: critical = {1, 2} (* Violation! *)
This is the killer feature: TLC proves the specification is wrong, not just that one test case fails.
Integration:
class TLCValidator:
def validate(self, spec: str) -> Tuple[bool, List[TLCError]]:
# Create config file
config = f"SPECIFICATION Spec\n"
# Run TLC
result = subprocess.run(
['java', '-cp', str(self.tlc_jar_path), 'tlc2.TLC',
'-workers', '4', spec_path],
capture_output=True,
timeout=300 # 5 minute timeout
)
errors = self._parse_tlc_output(result.stdout)
return len(errors) == 0, errors
Stage 6: Refinement Loop
When validation fails, the system will feed errors back to the LLM:
def refine(self, spec: str, errors: List[ValidationError], max_iterations: int = 5):
for i in range(max_iterations):
is_valid, new_errors = self.validator.validate(spec)
if is_valid:
return spec
# Build refinement prompt
error_summary = self._format_errors(new_errors)
refinement_prompt = f"""
The following TLA+ specification has errors:
{spec}
Errors:
{error_summary}
Fix these errors and regenerate a valid specification.
"""
spec = self.generator.generate(refinement_prompt)
raise RefinementError("Could not generate valid spec after {max_iterations} attempts")
Target Success Rates:
| Iteration |
Syntax Valid (Goal) |
Semantically Valid (Goal) |
| 1 |
40-50% |
20-30% |
| 2 |
70-80% |
50-60% |
| 3 |
85-90% |
70-80% |
| 4+ |
>90% |
>80% |
The iterative approach should be essential—preliminary testing suggests one-shot generation rarely works for complex specifications.
Design Decisions & Tradeoffs
Why Not Just Use GPT-4?
Cost Analysis:
| Approach |
Cost per Spec |
Notes |
| GPT-4 API |
$0.15 |
5K tokens in/out, 3 iterations |
| Llama 3.2 (self-hosted) |
$0.001 |
Inference on local GPU |
| Llama 3.2 (cloud GPU) |
$0.02 |
AWS g5.xlarge instance |
At 1,000 specs generated:
- GPT-4: $150
- Self-hosted Llama: $1
- Cloud Llama: $20
Fine-Tuning Control:
With open models, I’ll be able to:
- Train on proprietary TLA+ specs (companies can’t send to OpenAI)
- Control the training data distribution
- Debug model behavior by inspecting weights
- Deploy on-premise (critical for security-sensitive applications)
Why Iterative Refinement?
Alternative: Multi-Agent Generation
Some systems use multiple LLM calls in parallel:
- Agent 1: Generate spec
- Agent 2: Generate invariants
- Agent 3: Generate test cases
This is faster (parallel) but more expensive (3x API calls) and less coherent (agents don’t communicate).
Iterative refinement is sequential but should produce higher quality output because each iteration learns from validation feedback.
Why TLA+ First?
Alternative Targets:
| Language |
Pros |
Cons |
| Alloy |
Simpler syntax, better for relational models |
Weaker temporal logic |
| Z Notation |
Mature, used in safety-critical systems |
Harder to tool |
| Coq |
Theorem prover, ultimate verification |
Extremely steep learning curve |
| TLA+ |
Best temporal logic support, tooling (TLC), AWS/MS use it |
Unfamiliar syntax |
TLA+ hits the sweet spot of expressiveness (temporal logic), tooling (TLC model checker), and industry adoption (AWS, Azure).
The Roadmap
I’m building Symbolic in phases over the next 12 weeks:
Phase 1: Foundation (Weeks 1-3)
- Core architecture implementation
- Preprocessor and postprocessor
- Basic validation pipeline integration
Phase 2: Fine-Tuning (Weeks 4-8)
- Dataset creation (target: 5,000+ NL-TLA+ pairs)
- Model fine-tuning with LoRA
- Evaluation and iteration
Phase 3: Refinement & Polish (Weeks 9-12)
- Iterative refinement loop
- CLI tool development
- Documentation and examples
Future Goals:
- Multi-language support (Alloy, Z notation, SPIN)
- VS Code extension with real-time validation
- Web interface for non-technical users
- Formal verification as a service API
The ultimate goal: make formal methods as ubiquitous as unit testing.
Follow Along
I’m building this project in public and documenting the journey on this blog and on GitHub. Over the coming weeks, I’ll be sharing:
- Deep dives into TLA+ concepts and why they matter
- Technical posts on fine-tuning LLMs for specialized domains
- Lessons learned from building synthetic datasets
- Performance metrics as the system improves
- Open source code when it’s ready for early testing
If you’re interested in formal methods, LLM fine-tuning, or just want to see a project built from scratch, subscribe or follow the GitHub repository (link coming soon).
What would you want to formally verify? I’m collecting use cases and example systems to test Symbolic against. Reach out at timothy.c.dunbar@me.com if you have ideas or want to collaborate.
Further Reading
This is part 1 of a series on building Symbolic. Next up: “I Spent 40 Hours Learning TLA+ So You Don’t Have To” - a practical guide to the 5 core concepts.
]]>
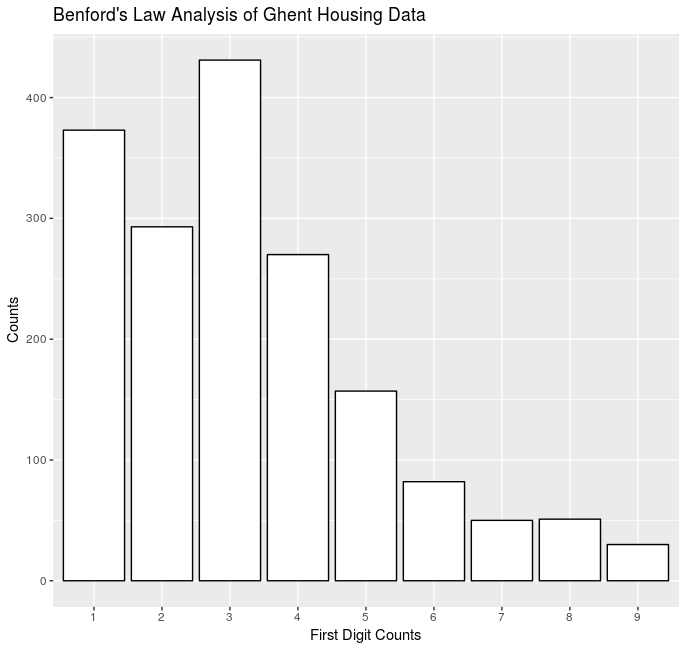
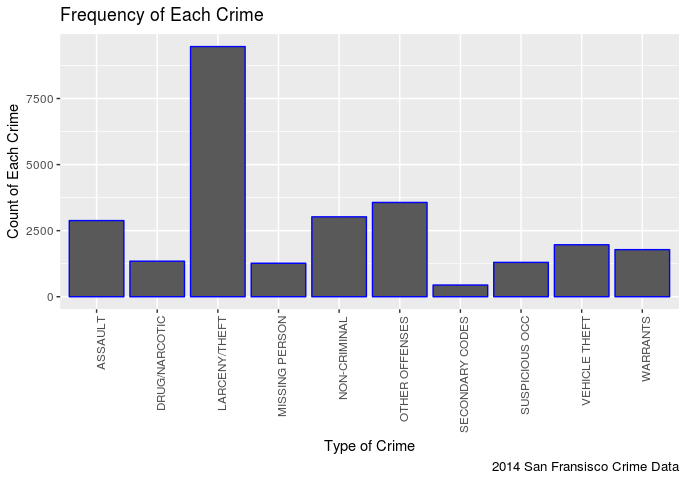 In my opinion this is pretty predictable, it seems there are more incidents of Larceny/Theft then any other crime.
In my opinion this is pretty predictable, it seems there are more incidents of Larceny/Theft then any other crime.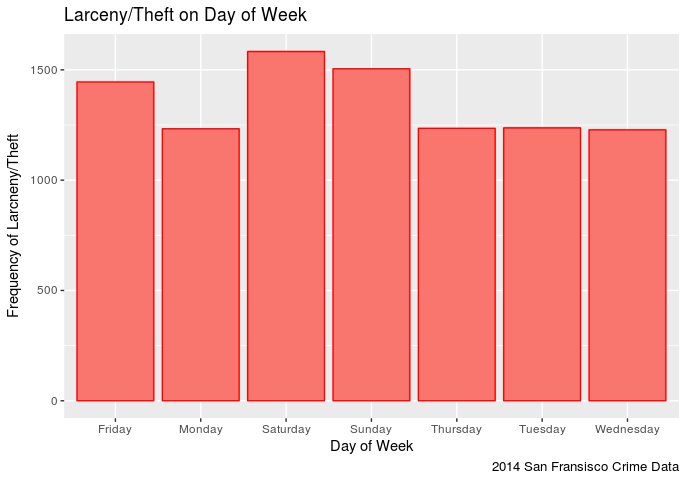 It appears that one has a slightly higher chance of being stolen from on a Saturday in San Fransisco (in 2014) than any other day. Though Sunday comes close followed by Friday. This makes sense in that the weekend seems to be the time when more assualts occur. It is also interesting to note that Larceny/Theft occurances on Monday-Thursday remain pretty steady.
It appears that one has a slightly higher chance of being stolen from on a Saturday in San Fransisco (in 2014) than any other day. Though Sunday comes close followed by Friday. This makes sense in that the weekend seems to be the time when more assualts occur. It is also interesting to note that Larceny/Theft occurances on Monday-Thursday remain pretty steady.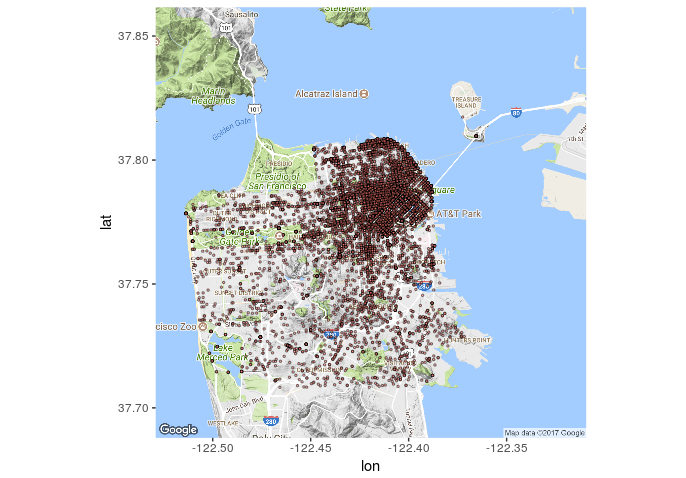 It seems that most of the reported thefts (in 2014) occured in that north east quadrant. To bad my data set doesn’t tell me what was stolen, it would be interesting to see how many of those were bike thefts (I dig bikes).
It seems that most of the reported thefts (in 2014) occured in that north east quadrant. To bad my data set doesn’t tell me what was stolen, it would be interesting to see how many of those were bike thefts (I dig bikes).